An Open-source Infrastructure for Modeling Dataflows within Deep Learning Accelerators
![]()
Hyoukjun Kwon , Prasanth Chatarasi, Vivek Sarkar, and Tushar Krishna
Georgia Institute of Technology
Michael Pellauer, Angshuman Parashar
NVIDIA
Emails: Please refer to our members page
News
- January 2020: MAESTRO has been selected for inclusion in IEEE Micro’s Top Picks from Computer Architecture 2020!
- Oct 15 2019: We presented MAESTRO at MICRO 2019
- Feb 16 2019: We ran a tutorial on MAESTRO at HPCA 2019
- Oct 23 2018: MAESTRO was in the final list at the ACM Student Research Competition (SRC)
- June 3, 2018: MAESTRO released at ISCA 2018 tutorial.
Overview
Deep learning techniques, especially convolutional neural networks
(CNN), have pervaded vision applications across image classification, face recognition, video processing, and so on due to the high degree of accuracy they provide. Both industry and academia are exploring specialized hardware accelerator ASICs as a solution to provide low-latency and high-throughput for CNN workloads.
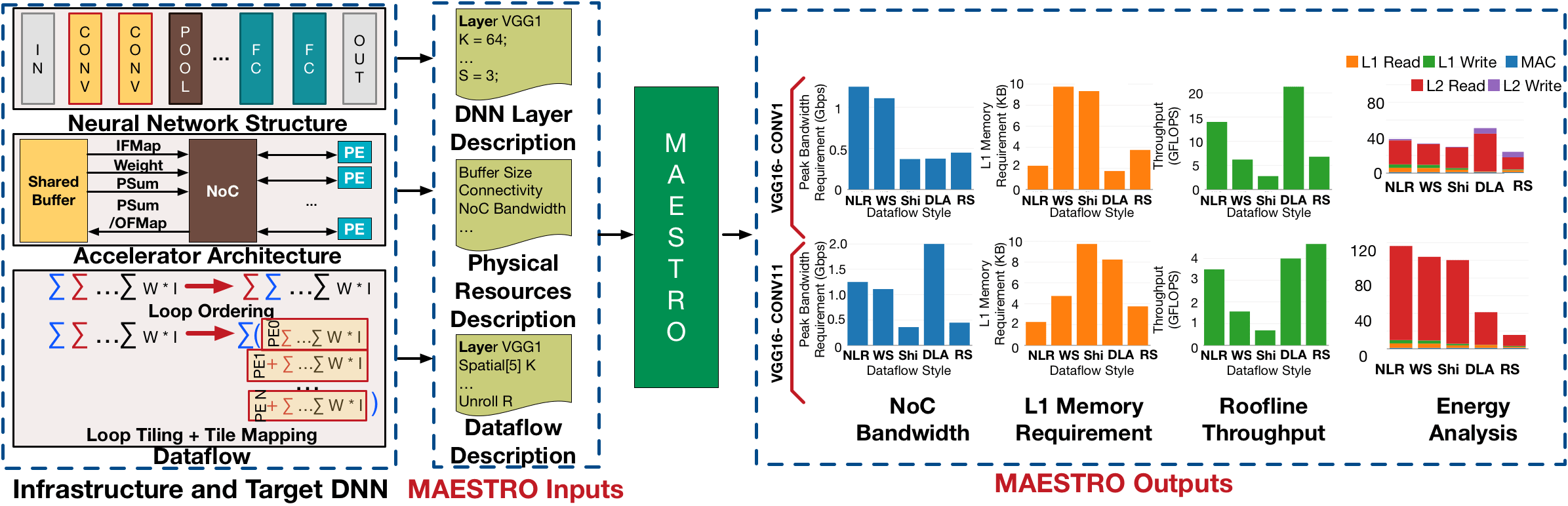
The convolution operation is a deeply nested multiply-accumulate loop. For throughput and energy efficiency, each accelerator chooses different strategies to manipulate the loop order/tiling of the convolution operations and the spatial/temporal mapping of data on compute units, which we collectively refer to as dataflow. The throughput and energy efficiency of a dataflow changes dramatically depending on both the DNN topology (i.e., layer shapes and sizes), and accelerator hardware resources (buffer size, and network-on-chip (NoC) bandwidth). This demonstrates the importance of dataflow as a first-order consideration for deep learning accelerator ASICs, both at design-time when hardware resources (buffers and interconnects) are being allocated on-chip, and compile-time when different layers need to be optimally mapped for high utilization and energy-efficiency.
We present MAESTRO (Modeling Accelerator Efficiency via
Spatio-Temporal Resource Occupancy), an open-source tool for
modeling and evaluating the performance and energy-efficiency of
different dataflows.
Key Features
- Concise date-centric descriptions to describe arbitrary dataflows for convolution, matrix multiplication, etc.
- An analysis framework that accepts the dataflow description, hardware resource description, and DNN layer description as inputs and generates latency, energy, buffer requirements, buffer access counts, network-on-chip (NoC) bandwidth requirements, and so on.
Update:
- We are actively working on to move the latest version in our dev-version repository to main-version repository. If you need the latest features (advanced convolution support, etc.) of MAESTRO, please refer to the dev-version.
Resources
- Talk Slides at MICRO 2019
- Tutorial at HPCA 2019 (Slides)
- Tutorial at ISCA 2018 (Slides + Video)
- Github Code Repository [main-version] [dev-version]
- MAERI – a DNN accelerator supporting flexible dataflows
Publications
Understanding Reuse, Performance, and Hardware Cost of DNN Dataflows: A Data-Centric Approach
Hyoukjun Kwon, Prasanth Chatarasi, Micheal Pellauer, Angshuman Parashar, Vivek Sarkar, and Tushar Krishna
MICRO 2019
[paper]