Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects
![]()
ASPLOS 2018 / SYSML 2018 / IEEE Micro 2018
IEEE Micro Top Picks 2018 – Honorable Mention
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna
Georgia Institute of Technology
Emails: Please refer to our members page
News
- Feb 16 2019: We ran a tutorial on MAERI at HPCA 2019
- Nov/Dec 2018: MAERI published in IEEE Micro Special Issue on Hardware Accelerators
- June 3, 2018: MAERI released at ISCA 2018 tutorial.
- Jan 17, 2018: MAERI is accepted in SysML 2018!
- Nov 14, 2017: MAERI paper is accepted in ASPLOS 2018!
Overview
 Tool Flow
Tool Flow
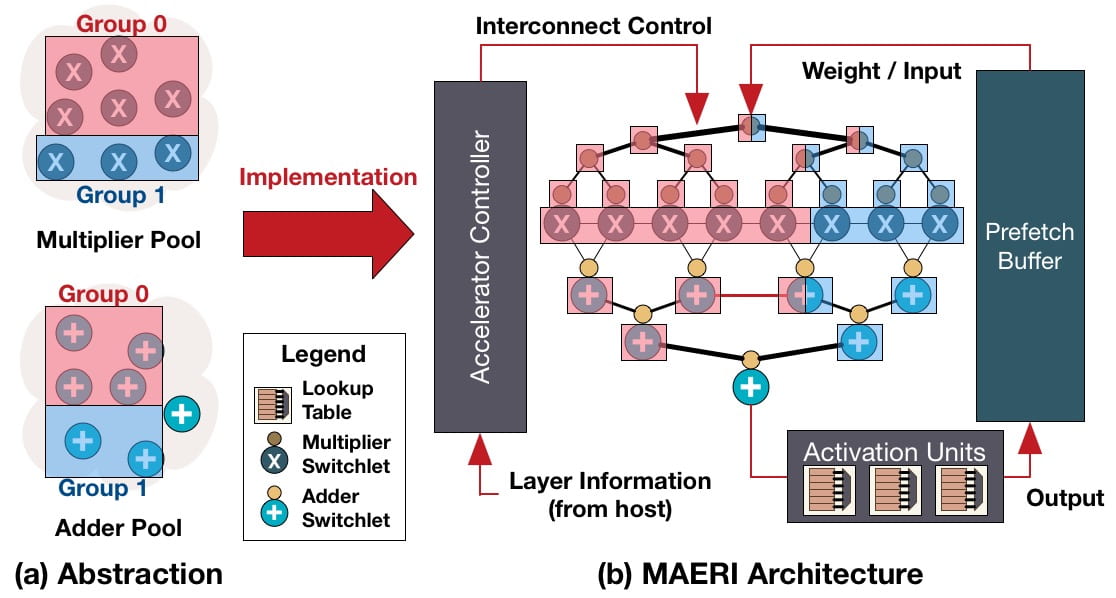
MAERI (Multiply-Accumulate Engine with Reconfigurable Interconnects) is a modular design-methodology for building DNN accelerators. It provides an efficient mapping of neural networks, which covers various DNN layer types and dimensions, state-of-the-art partitioning strategies (inter-layer fusion, intra-layer tiling, etc.) data density optimizations (sparsity, compression, etc.), data reuse strategies (dataflow classes based on stationary data).
Features
- Fine-grained compute units
- Reconfigurable interconnects with high bandwidth
- CNN/RNN (LSTM) support
- Parametrized codebase with synthesizable RTL for ASIC/FPGA flow
Abstract
Deep neural networks (DNN) have demonstrated highly promising results across computer vision and speech recognition, and are becoming foundational for ubiquitous AI. The computational complexity of these algorithms and a need for high energy-efficiency has led to a surge in research on hardware accelerators. To reduce the latency and energy costs of accessing DRAM, most DNN accelerators are spatial in nature, with hundreds of processing elements (PE) operating in parallel and communicating with each other directly.
DNNs are evolving at a rapid rate, and it is common to have convolution, recurrent, pooling, and fully-connected layers with varying input and filter sizes in the most recent topologies.They may be dense or sparse. They can also be partitioned in myriad ways (within and across layers) to exploit data reuse (weights and intermediate outputs). All of the above can lead to different dataflow patterns within the accelerator substrate.
Unfortunately, most DNN accelerators support only fixed dataflow patterns internally as they perform a careful co-design of the PEs and the network-on-chip (NoC). In fact, the majority of them are only optimized for traffic within a convolutional layer. This makes it challenging to map arbitrary dataflows on the fabric efficiently, and can lead to underutilization of the available compute resources.
DNN accelerators need to be programmable to enable mass deployment. For them to be programmable, they need to be configurable internally to support the various dataflow patterns that could be mapped over them.
To address this need, we present MAERI, which is a DNN accelerator built with a set of modular and configurable building blocks that can easily support myriad DNN partitions and mappings by appropriately configuring tiny switches. MAERI provides 8-459% better utilization across multiple dataflow mappings over baselines with rigid NoC fabrics.
Resources
- Tutorial at HPCA 2019 (Slides)
- Tutorial at ISCA 2018 – Slides + Video
- Request RTL Codebase
- MAESTRO – An Analytical Model for DNN dataflows
Relevant Publications
mRNA: Enabling Efficient Mapping Space Exploration for a Reconfigurable Neural
Accelerator
Zhongyuan Zhao, Hyoukjun Kwon, Sachit Kuhar, Weiguang Sheng, Zhigang Mao, and Tushar Krishna
In Proc of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Mar 2019
[pdf][slides]
A Communication Driven Approach to Designing Flexible DNN Accelerators
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna
In IEEE Micro Special Issue on Hardware Acceleration, Nov/Dec 2018
[pdf]
MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna
In Proc of the 23rd ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Mar 2018
[pdf][bibtex][slides][poster][Request RTL]
MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Programmable Interconnects
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna
In Inaugural SysML Conference, Feb 2018
[pdf]
Rethinking NoCs for Spatial Neural Network Accelerators
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna
In Proc of 11th International Symposium on Networks-on-Chip (NOCS), Oct 2017
[pdf][bibtex][slides][Request RTL]